一、方法参数限制ARM64 有34个寄存器,包括 31 个通用寄存器( x0-x30)、SP、PC、CPSR。
x0 – x30 是31个通用整型寄存器。每个寄存器可以存取一个 64 位大小的数。 当使用 r0 – r30 访问时,它就是一个 64 位的数。当使用 w0 – w30 访问时,访问的是这些寄存器的低 32 位。


Xcode 在真机中运行项目,添加断点 LLDB 中查看各寄存器状态register read。

CPU 由寄存器、运算器、控制器三部分组成,其中寄存器的主要作用是用于存储信息。可以理解为是内存的一种,但是比内存高效的多。ARM64 中 X0 – X7 寄存器主要用于子程序调用时的参数传递,如果方法传递的参数过多,寄存器不够使用,此时会将多余的参数直接存放于函数调用栈中。而栈主要存在于内存中,相比寄存器而言速度会慢很多,所以 iOS 实际开发中应注意参数传递个数,参数传递过多,一定程度会降低代码执行速度。不同平台情况不一样,64 位 ATT 汇编中 %rdi、%rsi、%rdx、%rcx、%r8、%r9、%r10等寄存器用于存放函数参数,还有一些平台可能直接使用栈保存函数参数,此种情况理论上参数个多对代码执行效率没有太多影响。
int sum(int a,int b,int c, int d,int e,int f,int g,int h,int i,int j,int k){
return a + b + c + d + e + f + g + h;
int main(int argc, const char * argv[]) {
@autoreleasepool {
int num = sum(1,2,3,4,5,6,7,8,9,10,11);
NSLog(@”%d”,num);
return 0;
上述代码对应的 64 位ATT 汇编代码如下。仔细观察下面汇编代码,从第 13 行开始,涉及 rsp 指针的加减操作,说明之后的参数存在于栈区(对栈进行读写的内存地址编号是由 rsp 寄存器进行管理的。push 指令和 pop 指令运行后,esp 寄存器的值会自动进行更新,push 指令 rsp 减少,pop 命令 rsp 增加)。 也即前 7 个参数存在于寄存器中(%rdi、%rsi、%rdx、%rcx、%r8、%r9、%r10),后 4 个参数保存在栈中。
0x100000eb2 +34: movl $0x1, %edi
0x100000eb7 +39: movl $0x2, %esi
0x100000ebc +44: movl $0x3, %edx
0x100000ec1 +49: movl $0x4, %ecx
0x100000ec6 +54: movl $0x5, %r8d
0x100000ecc +60: movl $0x6, %r9d
0x100000ed2 +66: movl $0x7, %r10d
0x100000ed8 +72: movl $0x8, %r11d
0x100000ede +78: movl $0x9, %ebx
0x100000ee3 +83: movl $0xa, %r14d
0x100000ee9 +89: movl $0xb, %r15d
0x100000eef +95: movl $0x7, (%rsp)
0x100000ef6 +102: movl $0x8, 0x8(%rsp)//第13行
0x100000efe +110: movl $0x9, 0x10(%rsp)
0x100000f06 +118: movl $0xa, 0x18(%rsp)
0x100000f0e +126: movl $0xb, 0x20(%rsp)
0x100000f16 +134: movq %rax, -0x40(%rbp)
0x100000f1a +138: movl %r15d, -0x44(%rbp)
0x100000f1e +142: movl %r14d, -0x48(%rbp)
0x100000f22 +146: movl %ebx, -0x4c(%rbp)
0x100000f25 +149: movl %r11d, -0x50(%rbp)
0x100000f29 +153: movl %r10d, -0x54(%rbp)
0x100000f2d +157: callq 0x100000e30 ; sum at main.m:11
二、反汇编 switch case if else2.1 反汇编 if else
int a = 1;
if (a 1) {
NSLog(@”a 1″);
}else if(a 2){
NSLog(@”a 2″);
}else{
NSLog(@”a = 1″);
上述代码对应的汇编代码如下。第 3 行表示比较 1 和 a 的值,第 5 行表示如果 a = 1,则跳转到指令0x100000f16处,也即第 11 行,其中 jle 中的 l 和 e 的含义分别是 lower 和 equal; 否则输出 a 1,对应第 6 行。后面的判断依次类推,依次对if 、else if分支做判断,找到对应的分支后,直接跳过所有分支。
1 、0x100000ee6 +22: callq 0x100000f6a ; symbol stub for: objc_autoreleasePoolPush
2、 0x100000eeb +27: movl $0x1, -0x14(%rbp)
3、0x100000ef2 +34: cmpl $0x1, -0x14(%rbp)
4、0x100000ef6 +38: movq %rax, -0x20(%rbp)
5、0x100000efa +42: jle 0x100000f16 ; +70 at main.m:16
6、0x100000f00 +48: leaq 0x121(%rip), %rax ; @”a 1″
7、0x100000f07 +55: movq %rax, %rdi
8、0x100000f0a +58: movb $0x0, %al
9、0x100000f0c +60: callq 0x100000f5e ; symbol stub for: NSLog
10、0x100000f11 +65: jmp 0x100000f4c ; +124 at main.m:21
11、0x100000f16 +70: cmpl $0x2, -0x14(%rbp)
12、0x100000f1a +74: jle 0x100000f36 ; +102 at main.m
13、0x100000f20 +80: leaq 0x121(%rip), %rax ; @”a 2″
14、0x100000f27 +87: movq %rax, %rdi
15、0x100000f2a +90: movb $0x0, %al
16、0x100000f2c +92: callq 0x100000f5e ; symbol stub for: NSLog
17、0x100000f31 +97: jmp 0x100000f47 ; +119 at main.m
18、0x100000f36 +102: leaq 0x12b(%rip), %rax ; @”a = 1″
19、0x100000f3d +109: movq %rax, %rdi
20、0x100000f40 +112: movb $0x0, %al
21、0x100000f42 +114: callq 0x100000f5e ; symbol stub for: NSLog
22、0x100000f47 +119: jmp 0x100000f4c ; +124 at main.m:21
23、 0x100000f4c +124: movq -0x20(%rbp), %rdi
24、0x100000f50 +128: callq 0x100000f64 ; symbol stub for: objc_autoreleasePoolPop
顺便补充一点,当编译器的Optional Level设置为Fastest,Smallest[-OS]是,会发现汇编代码少了前面两个分支的判断直接来到最后的else分支,这是因为编译器对代码做了优化,所以一般打 release 包,往往选择这个选项。
2.2 反汇编switch case
int a = 5;
switch (a) {
case 1:
NSLog(@”1″);
break;
case 2:
NSLog(@”2″);
break;
case 3:
NSLog(@”3″);
break;
case 4:
NSLog(@”4″);
break;
case 5:
NSLog(@”5″);
break;
default:
NSLog(@”default”);
break;
上述代码对应的汇编代码如下。第 1 行表明如果不满足各种 case 条件,直接来到 default 分支。第 6 行中的 rdx寄存器是重点,里面保存着下一条指令的地址,LLDB 中输入p/x $rdx,输出结果为(unsigned long) $0 = 0x0000000100000f09,也即直接到case 为 5 的分支,其中的 x 表示打印 16 进制,$是打印寄存器值的标识符号。第四行相当于rdx = rax + rcx * 4,也即利用基址加上 间隔 * 4 找到下一条指令的位置,总的来说内部实现是空间换时间的做法,所以理论上 switch case 的效率要优于 if else。但是有一种特殊情况,当各个 case 值相差较大时,不可能提前创建好一大片连续空间,否则会造成空间的严重浪费,此种情况反汇编出的代码基本和 if else 的逻辑类似,此时两者的效率大致是等价的。
1、0x100000e97 +55: ja 0x100000f1f ; +191 at main.m
2、0x100000e9d +61: leaq 0xa0(%rip), %rax ; main + 228
3、0x100000ea4 +68: movq -0x28(%rbp), %rcx
4、0x100000ea8 +72: movslq (%rax,%rcx,4), %rdx
5、0x100000eac +76: addq %rax, %rdx
6、0x100000eaf +79: jmpq *%rdx
7、0x100000eb1 +81: leaq 0x170(%rip), %rax ; @”‘1′”
8、0x100000eb8 +88: movq %rax, %rdi
9、0x100000ebb +91: movb $0x0, %al
10、0x100000ebd +93: callq 0x100000f58 ; symbol stub for: NSLog
11、0x100000ec2 +98: jmp 0x100000f30 ; +208 at main.m:44
12、0x100000ec7 +103: leaq 0x17a(%rip), %rax ; @”‘2′”
13、0x100000ece +110: movq %rax, %rdi
14、0x100000ed1 +113: movb $0x0, %al
15、0x100000ed3 +115: callq 0x100000f58 ; symbol stub for: NSLog
16、0x100000ed8 +120: jmp 0x100000f30 ; +208 at main.m:44
17、0x100000edd +125: leaq 0x184(%rip), %rax ; @”‘3′”
18、0x100000ee4 +132: movq %rax, %rdi
19、0x100000ee7 +135: movb $0x0, %al
20、0x100000ee9 +137: callq 0x100000f58 ; symbol stub for: NSLog
21、0x100000eee +142: jmp 0x100000f30 ; +208 at main.m:44
22、0x100000ef3 +147: leaq 0x18e(%rip), %rax ; @”‘4′”
23、0x100000efa +154: movq %rax, %rdi
24、0x100000efd +157: movb $0x0, %al
25、0x100000eff +159: callq 0x100000f58 ; symbol stub for: NSLog
26、0x100000f04 +164: jmp 0x100000f30 ; +208 at main.m:44
27、0x100000f09 +169: leaq 0x198(%rip), %rax ; @”‘5′”
28、 0x100000f10 +176: movq %rax, %rdi
29、0x100000f13 +179: movb $0x0, %al
30、0x100000f15 +181: callq 0x100000f58 ; symbol stub for: NSLog
31、 0x100000f1a +186: jmp 0x100000f30 ; +208 at main.m:44
32、0x100000f1f +191: leaq 0x1a2(%rip), %rax ; @”default”
33、0x100000f26 +198: movq %rax, %rdi
34、0x100000f29 +201: movb $0x0, %al
35、0x100000f2b +203: callq 0x100000f58 ; symbol stub for: NSLog
PS:不是很熟悉汇编,只是简单做一些了解,写的很浅显。
三、C 中写汇编代码由于汇编更接近机器语言,能够直接对硬件进行操作,生成的程序与其他的语言相比具有更高的运行速度,占用更小的内存,因此在一些对时效性要求很高的程序,大型程序的核心模块以及工业控制方面大量应用。很多 C 语言三方库为了提升代码执行效率,有时会在 C 代码中插入汇编语言,比如 OC 的 runtime 源码中,其中就有部分代码是汇编代码。这里就举个简单的例子,以 ATT 汇编实现int add(int a, int b)函数。简单说明下 ATT 汇编中,%rax作为函数返回值使用,%rdi、%rsi、%rdx、%rcx、%r8、%r9、%r10等寄存器用于存放函数参数。
//add.h 文件
#ifndef add_h
#define add_h
int add(int a, int b);
#endif /* add_h */
//add.s 文件
//1、.global _add 表示公开方法,否则是私有方法
//2、汇编代码对应的函数名要加 _
//3、di 和 si 一般用于存放参数,ax用于存放返回值
.global _add
_add:
//rdi寄存器存放的参数赋值给rax寄存器
movq %rdi,%rax;
//rsi寄存器存放的参数加上rax寄存器值,然后赋值给rax
addq %rsi,%rax
//函数调用结束
retq
另外,很多高级语言底层都是 C 或 C++ 编写,一些对性能要求比较高的地方,必要时候可以混入 C 或 C++ 代码。比如移动端高德地图上很多线路等底层绘制都是通过 OpenGL 完成。如果想在高德地图上绘制上自己的相关需求模型,可以借助 C++ 编写 OpenGL 相关代码。该种方式要比直接在地图上直接自定义控件等方式效率要高上很多。
四、 __builtin_expect 分支执行概率(贪心算法思路数据压缩)4.1 __builtin_expect
__builtin_expect 是对 if 语句的预言,该指令可以告诉编译器最有可能执行的代码,从而编译器进行优化,通俗来讲就是告诉编译器执行 if 和 else 哪个是大概率事件。__builtin_expect(EXP, N) 表示 EXP == N 是大概率事件。
CFAbsoluteTime startTime = CFAbsoluteTimeGetCurrent();
int a = 3;
for (int i = 0; i 100000; i++) {
if (a == 1) {
[self doSomething];
}else if(a == 2){
[self doSomething];
}else if (a == 3){
[self doSomething];
}else{
[self doSomething];
CFAbsoluteTime endTime = CFAbsoluteTimeGetCurrent();
NSLog(@”%f”,endTime – startTime);
CFAbsoluteTime startTime = CFAbsoluteTimeGetCurrent();
int a = 3;
for (int i = 0; i 100000; i++) {
if (__builtin_expect(a,3)) {
[self doSomething];
}else if(a == 2){
[self doSomething];
}else if (a == 3){
[self doSomething];
}else{
[self doSomething];
CFAbsoluteTime endTime = CFAbsoluteTimeGetCurrent();
NSLog(@”%f”,endTime – startTime);
用上述代码做了三次实验,三次结果时间如下。显然使用__builtin_expect,代码效率提升了不少。这里要注意,对于一些非常简单的分支判断,该优化可能仅在 debug 模式下有效,因为对于一些简单的分支判断, release 模式下编译器会进行代码优化。
第一次:0.001160 0.000917
第二次:0.001302 0.000598
第三次:0.001436 0.001010
4.2 压缩技术(贪心算法)
实际开发中应该注意if 和 else if 或 else 分支执行的概率,对于执行概率相对比较大的分支应该放相对靠前的位置。赫夫曼压缩技术其实主要是基于分支概率进行的,具体可以参照此篇文章浅谈赫夫曼树及其应用(文件压缩)。
顺便补充一下,赫夫曼压缩技术实际上是贪心算法思路。贪心算法一般只着眼于眼前,并不会考虑后续的太多事,解决的问题比较有限,压缩技术问题和实际生活中的找零钱问题,比较适合用此思路解决。假设我们有 1 、2 、5 、10 、20 、50、100 元这些面额的纸币,它们的张数分别是 c1、c2、c5、、c10、c20、c50、c100。我们现在要用这些钱来支付 K 元,最少要用多少张纸币呢?在生活中,我们肯定是先用面值最大的来支付,如果不够,就继续用更小一点面值的,以此类推,最后剩下的用 1 元来补齐。这其实就算是贪心算法思路。
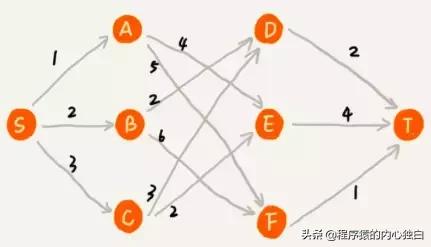
实际上,用贪心算法解决问题的思路,并不总能给出最优解。在一个有权图中,我们从顶点 S 开始,找一条到顶点 T 的最短路径(路径中边的权值和最小)。贪心算法的解决思路是,每次都选择一条跟当前顶点相连的权最小的边,直到找到顶点 T。按照这种思路,我们求出的最短路径是 S-A-E-T,路径长度 1+4+4=9 。然而,路径 S-B-D-T 才是最短路径,这条路径的长度2+2+2=6。产生错误的原因在于,前面的选择,会影响后面的选择,贪心算法仅仅看中眼前,并没有考虑以后。
五、递归和迭代的选择5.1 计算机的思维方式
人有人的思维,计算机有计算机的思维,人的正向思维被称为递推,计算机的逆向思维被称为递归。递推是人本能的正向思维,如学习过程就是从易到难,有小到大,由局部到整体,数学归纳法就是递推的典型应用。递归的本质是自顶向下不断地重复。如求解 10! ,按照正向思维就是 1 x 2 x 3 x 4…… x 10。而计算机计算阶乘是反着来的,会把 10! 变为 10 x 9!,9!变为 9 x 8!…….如此向下扩展一直到1! = 1。接着就是推回所有结果,知道了 1!之后,其他 2!、3! 、4! ….就都知道了。递归的过程是从上向下展开,再从下到上回溯,和栈的结构非常类似,即先进后出,后进先出。从上往下展开的顺序是10,9…..1,从下往上回溯的顺序是1…..10 。当栈里的数字清空时,递归算法也就结束了。计算机之所以采用这种计算方式,是因为递归每一步用的算法都相同,计算机仅需要自顶向下不断地重复。如从尾到头打印链表,有两种方案,一种是借助栈,一种是递归。其实递归方案本质也是借用栈。注意在递归前和递归后打印数据的区别,递归前执行的代码相当于入栈操作,递归后执行的代码相当于出栈操作。
//栈方案
– (void)printListReversinglyOne:(ListNode *)list{
NSMutableArray *arr = [NSMutableArray array];
ListNode *listNode = list;
while (listNode != nil) {
//入栈
[arr addObject:listNode.value];
listNode = listNode.next;
for (NSInteger i = arr.count – 1; i = 0 ; i–) {
NSLog(@”栈方法:%@”,arr[i]);
//注意在递归前和递归后打印数据的区别,递归前执行的代码相当于入栈操作,递归后执行的代码相当于出栈操作。
//递归方案
– (void)printListReversinglyTwo:(ListNode *)list{
//1、递归必须有终止条件
if (list == nil) {
return;
//2、这里是正序输出。相当于入栈做的操作。
//NSLog(@”递归方法:%@”,list.value);
//3、这里相当于入栈,有递归的时候就没有while或者for循环。
[self printListReversinglyTwo:list.next];
//4、这里是逆序输出。相当于出栈操作,因为这里已经出了递归函数内部。
NSLog(@”递归方法:%@”,list.value);
5.2 递归的优缺点
递归优点:
递归最大的优点是代码简洁,对于计算机而言只是重复,思路简洁。但对于人类而言,虽易于理解但没有递推思路计算简单。
递归缺点:
1、栈深度问题通常会出现在递归中。因为程序在递归时,函数调用本身也是一种消耗,函数调用需要在内存栈中分配空间保存参数、返回地址和临时变量。一般来说栈是向下生长的,所以递归调用的深度过多,就会造成栈空间存储不足。出现栈溢出现象,引发不可预知的错误或崩溃。2、可能存在重复,如下面的斐波那契数列递归。对于递归方式: f(10) = f(9) + f(8); f(9) = f(8) + f(7); f(8) = f(7) + f(6)…..会发现整个递归环节除了 f(10) 和 f(0) 是计算一遍,其他都需要计算两次,有不少的重复计算。所以如果用 for 循环的解决的话,效率会高于递归。为了避免该问题,可以缓存相应的计算结果,减少重复计算。- (int)recursionFibonacci:(int)n{
if (n == 0) {
return 0;
if (n == 1) {
return 1;
//这里相当于函数入栈
return [self recursionFibonacci:n-1] + [self recursionFibonacci:n-2];
六、空间换时间空间换时间这里简单列出四个例子:C++中的内联函数、大数据排序问题、典型的归并排序算法以及一道比较常见的算法面试
6.1 内联函数
参照文章小知识点 包体积优化中的内联函数
6.2 大数据排序问题
参照文章小知识点 如何给百万数据排序
6.3 归并排序
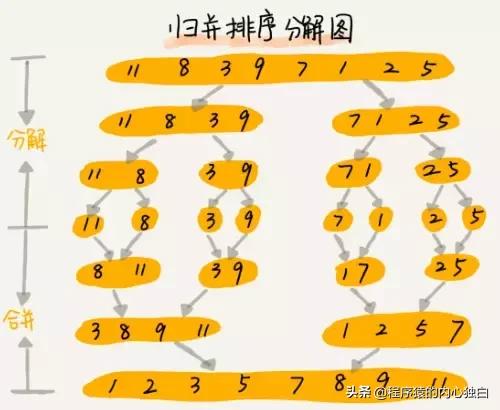
归并排序最终的结果合并是很典型的空间换时间思路。归并排序的核心思想把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。其中的合并过程就主要利用过了空间换时间的思路,新创建一个数组,将原本产生的另个数组中的内从按照顺序从小到大或从大到小依次放入到新创建的数组中。
6.4 组中是否存在两个数字之和等于某个数。
已知一个整形数组(arr)以及一个整数(sum),判断数组中是否存在两个数字之和等于这个整数(sum)?最直接的方法可能是两层 for 循环遍历数组,第一层循环是每次取一个值 a,第二层循是判断这个数组中是否存在一个值等于 sum – a,这样做的时间复杂度是 O(n^2),但是借助集合就能将时间复杂度降为 O(n)。实现思路是: 遍历数组的时候,用集合保存已经遍历过的元素。在下一次遍历的过程中,如果集合中存在一个值等于 sum 减去当前遍历的值,则说明数组中存在一个数等于sum 减去当前遍历的数值。
func isExist(arr:[Int],sum:Int) – Bool {
var set = SetInt()
for num in arr {
if set.contains(sum – num){
return true
set.insert(num)
return false
如果要求具体的下标,可以借助字典来实现。
func getIndex(arr:[Int],sum:Int)-[Int]{
var dict = [Int:Int]()
for (i,num) in arr.enumerated(){
if let idx = dict[sum-num]{
return [idx,i]
}else{
dict[num] = I
fatalError(“没有满足条件的下标”)
七、栈区和堆区7.1 Swift 中的结构体
Swift中,值类型都是存在栈中的,引用类型都是存在堆中的。苹果官网上明确指出建议开发者多使用值类型。主要有以下原因:
数据结构方面
1、存放在栈中的数据结构较为简单,只有一些值相关的东西。2、存放在堆中的数据较为复杂,会包含 type、retainCount 等。数据的分配与读取方面
1、存放在栈中的数据从栈区底部推入 (push),从栈区顶部弹出 (pop),类似一个数据结构中的栈。由于我们只能够修改栈的末端,因此我们可以通过维护一个指向栈末端的指针来实现这种数据结构,并且在其中进行内存的分配和释放只需要重新分配该整数即可。所以栈上分配和释放内存的代价是很小。2、存放在堆中的数据并不是直接 push/pop,类似数据结构中的链表,需要通过一定的算法找出最优的未使用的内存块,再存放数据。同时销毁内存时也需要做一些额外操作。7.2 C++ 中的对象
iOS 开发者经常会听到值类型存放在栈区,对象类型存放在堆区。但并不是所有的对象都存在堆区中,比如 C++ 中的对象可以存在去全局区、堆区也可以存在栈区。所以某些情况下,可以考虑堆、栈中创建对象的平衡性,使性能相对比较稳定。
struct Person {
int m_age;
// 全局区
Person g_person;
int main() {
// 栈空间
Person person;
// 堆空间
Person *p = new Person();
p-m_age = 20;
delete p;
return 0;
八、其他数组下标为何从零开始
数组下标最确切的定义应该偏移(offset),如果用 a 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[k] 就表示偏移 k 个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:
a[k]_address = base_address + k * type_size
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
a[k]_address = base_address + (k-1)*type_size
对比两个公式,不难发现,从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。